Data di aggiornamento
Il portale dati.gov.it rappresenta il punto di accesso unico ai dati aperti delle pubbliche amministrazioni italiane come indicato dall’art. 9 del D. Lgs. n. 36/2006, norma che include il recepimento della Direttiva 2019/1024, cosiddetta Direttiva Open Data.
In attuazione delle disposizioni del citato decreto, la pubblicazione dei metadati sul Catalogo nazionale dei Dati Aperti, è uno specifico requisito definito nelle Linee Guida recanti regole tecniche per l’apertura dei dati e il riutilizzo dell’informazione del settore pubblico, insieme agli altri requisiti di qualità e completezza dei metadati.
Il portale, basato sull’integrazione del CMS Drupal e della piattaforma DMS CKAN, raccoglie i metadati dei dati aperti sulla base dello standard definito a livello europeo e opportunamente esteso a livello nazionale denominato DCAT-AP_IT (Data Catalog Application Profile – Italia).
Esistono varie modalità per le PA per poter pubblicare correttamente i metadati relativi ai propri dataset.
Il Catalogo Nazionale viene alimentato generalment attraverso la funzione di harvesting, che consente di importare in maniera automatica i metadati relativi ai dataset che le pubbliche amministrazioni e le società che erogano servizi pubblici rendono disponibili come dati di tipo aperto sui propri cataloghi.
Pertanto, in via generale, è possibile contribuire allo sviluppo del catalogo nazionale federando il proprio catalogo con il portale dati.gov.it. I metadati raccolti ed esposti dal catalogo nazionale dati.gov.it confluiscono poi nel Portale europeo dei dati aperti data.europa.eu.
Un catalogo “locale” può contenere solo i metadati dei dati dell’amministrazione titolare o, in un’azione di sussidiarietà, può raccogliere anche i metadati di altre pubbliche amministrazioni fungendo in questo modo da intermediario per il catalogo nazionale.
In questo ultimo caso, i vari soggetti intermedi (che possono essere Regioni, Unioni dei Comuni, Province Autonome o Città Metropolitane) fungono da importatori (harvester) dei metadati degli Enti sotto-ordinati e contemporaneamente da importati (harvested) da parte di dati.gov.it t. Questo senza interventi manuali e senza cambiare la titolarità del Dataset che rimane sempre in capo alla PA produttrice iniziale.
Di seguito vengono descritte le specifiche procedure per la pubblicazione dei metadati nel portale dati.gov.it.
1. Inserimento manuale attraverso l'editor
Per le PA, soprattutto piccole, che non hanno le possibilità tecnologiche, tecniche, economiche e strumentali per implementare propri cataloghi di dati e non rientrano in azioni di sussidiarietà da parte di amministrazioni sovraordinate, è disponibile uno strumento di editing attraverso cui compilare e pubblicare i metadati. L'editor è disponibile nell'area riservata del portale. Per informazioni su come accedere a tale area, leggere la relativa guida.
2. Pubblicazione attraverso harvesting
Nel caso non si utilizzi la modalità di cui al punto precedente, è possibile seguire le procedure indicate di seguito:
- esporre un proprio ENDPOINT, cioè una URL da comunicare ad AgID, in cui è presente l’elenco dei metadati coerenti con lo standard DCATAP_IT. I formati possono essere TTL , RDF (esempio);
- implementare un catalogo che automaticamente espone il file di cui al punto 1). Per esempio, un catalogo basato sulla piattaforma CKAN con l’estensione DCATAP_IT. In tal caso l’endpoint avrà un formato RDF (esempio Comune di piccole dimensioni, esempio Comune di grandi dimensioni, esempio Ente regionele (CCIAA Marche) con completezza metadati);
- esporre i propri dati e metadati costruendo manualmente il file RDF. Tale caso si verifica qualora non sia possibile implementare un proprio catalogo o perché il numero di dataset da esporre sia alquanto limitato che non giustificherebbe lo sviluppo di un catalogo. I dataset sono esposti, quindi, sul proprio sito istituzionale (o su piattaforme come GitHub).
- rendere disponibile un endpoint SPARQL che espone i metadati secondo lo standard DCATAP_IT. Il formato può essere .TTL o .RDF (esempio)
- utilizzare le API standard del proprio CMS (esempio DKAN o CKAN). In tal caso bisogna comunicare ad AgID l’URL della radice del proprio CMS (esempio).
Nella figura che segue è rappresentato lo schema di harvesting.
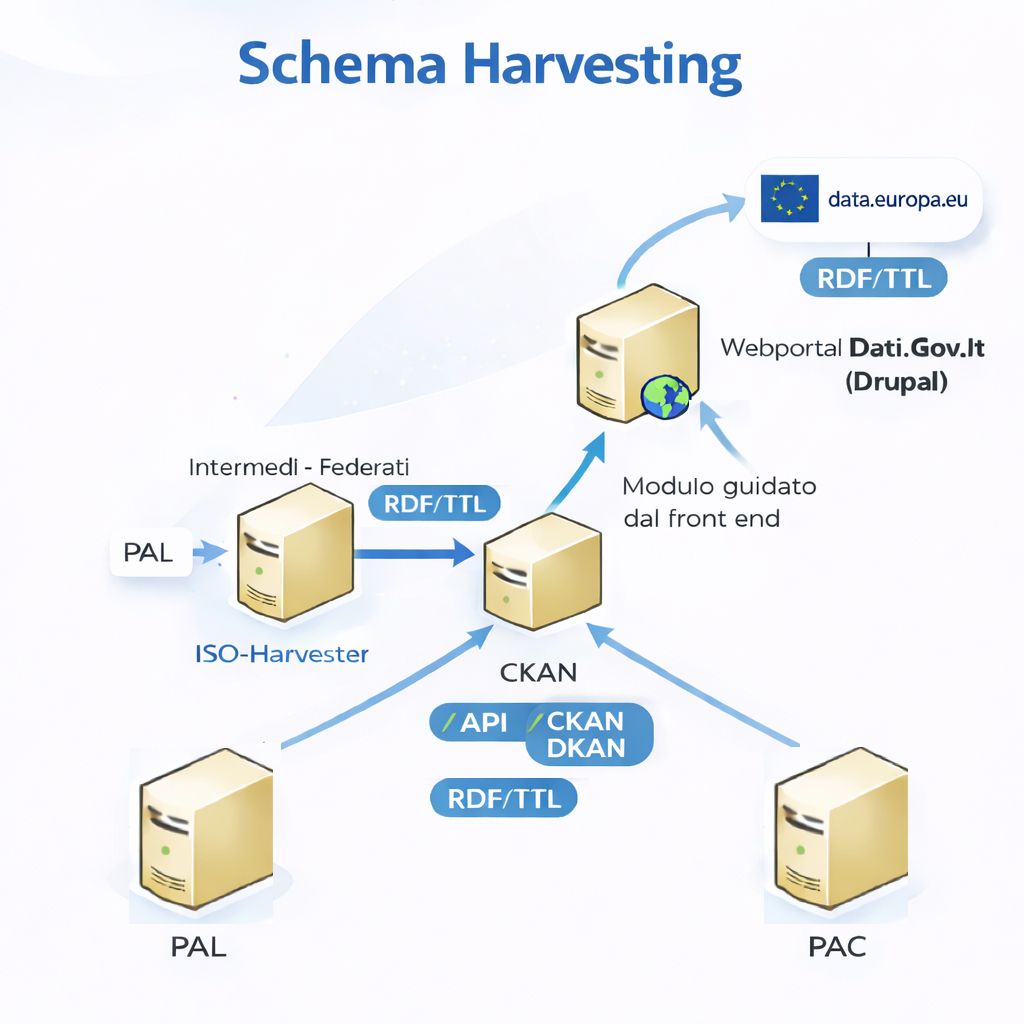
Si raccomanda di seguire in ogni caso le FAQ presenti dove sono spiegate nel dettaglio le procedure per correggere eventuali errori nei metadati (licenze, formati) o configurare le caratteristiche di CKAN per evitare errori nella qualità dei metadati stessi.
Comunicazione per la pubblicazione dei metadati
A prescindere dalla modalità scelta, i soggetti che intendono pubblicare i propri metadati su dati.gov.it possono utilizzare il form Scrivi alla redazione comunicando:
- Nome e cognome del referente del catalogo
- Indirizzo mail e riferimenti telefonici del referente del catalogo
- URL di accesso al catalogo (endpoint) o comunque ai metadati.
Nella sezione Elenco cataloghi federati è disponibile la lista dei cataloghi che alimentano il portale dati.gov.it.